Fair decisions don't need centralized data. They need stable decisions.
Federated learning was meant to solve a governance problem: banks, hospitals, and agencies can't — and in many jurisdictions, mustn't — pool raw data. Vertical federated learning (VFL) goes further: each institution holds different columns of the same people.
But fairness doesn't care that the data is split. A 25-year-old applicant still deserves a decision that wouldn't flip if she were 30 instead, holding her policy-relevant qualifications constant. Group-level fairness constraints — demographic parity, equalized odds — can be satisfied in aggregate while specific individuals still experience arbitrary flips under hypothetical sensitive-attribute changes.
And in VFL, three things make this harder:
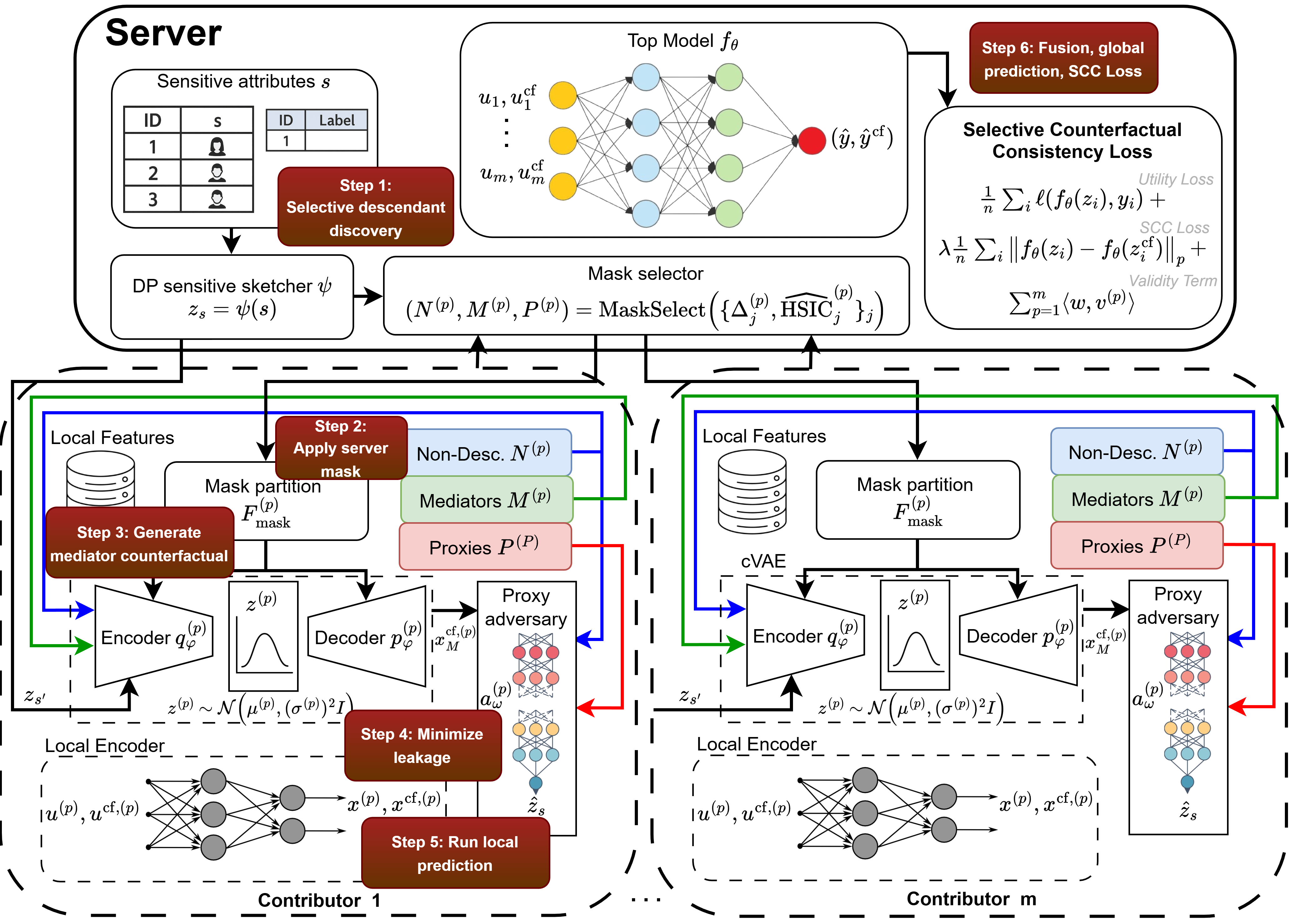
- The sensitive attribute may be held privately by one party.
- Proxies for it are scattered across institutions.
- Sensitive influence only emerges after aggregation at the server.
Most prior work either presumes a fully-specified causal graph (rarely available) or enforces representation invariance that blurs the line between legitimate pathways and impermissible proxies.
- The target: per-individual counterfactual stability, not group parity.
- The setting: features split across parties; sensitive attribute privately held.
- The mechanism: discover feature roles under DP, edit only policy-permitted mediators, enforce consistency at the server.
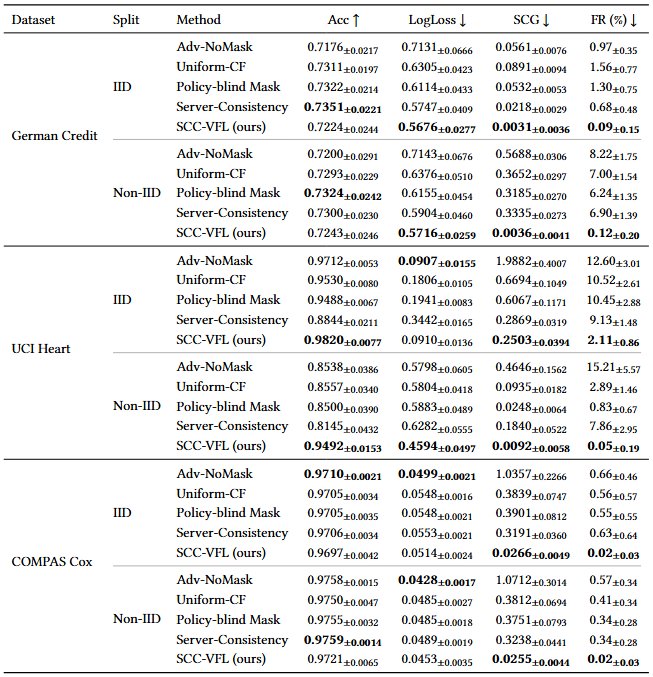
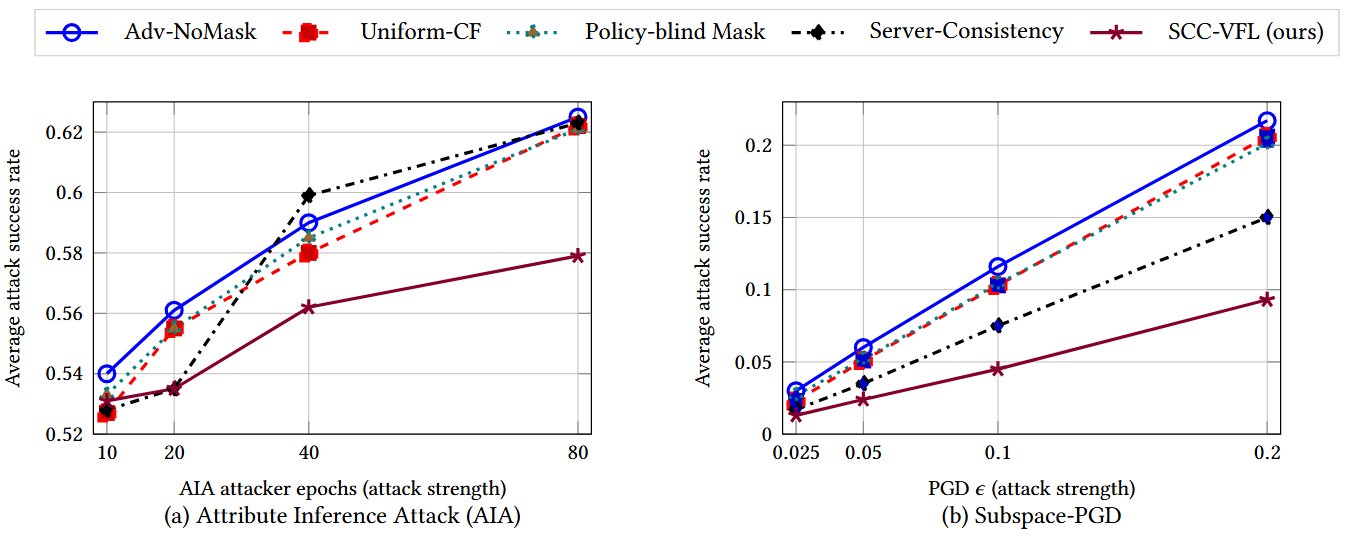
- The evidence: flip rates collapse by up to 98% on real credit / health / justice data, with attribute-inference leakage reduced.
- The caveat: consistency is not justice — the policy specification must still be defensible.